
不用部署免费使用?别被DeepSeek满血版欺骗!不同精度区别有多大
适用于追求卓越生成质量的场景,例如高级科研、企业级大模型推理,以及需要精确控制输出质量的应用。DeepSeek-R1 671B的“满血版”在不同精度下的推理效果差异巨大,因此在选择时需谨慎对比,不可盲目跟风。适用于对生成质量要求不高,但需要优质算力优化的场景,例如边缘计算、轻量级应用、或消费级硬件上的部署。适用于希望在保证较高质量的前提下降低显存占用和提升推理速度的场景,例如企业内部部署、云计算平
“不用部署!DeepSeek满血版免费使用!”
“5分钟用上DeepSeek满血版!”
“不卡顿!DeepSeek满血版直接白嫖!”
近期,市场上出现了许多关于“DeepSeek满血版”的宣传,部分宣传声称,某些特定优化版本仍然能保持完整的模型能力!
实际上,只要是DeepSeek 671B的模型,都可以被冠以“满血版”的名号,但它们的实际推理效果却大相径庭。本文将深入分析不同精度(FP16、INT8、INT4)对模型推理性能的影响,帮助大家避免踩坑。
一、“满血版”到底是什么意思
目前,DeepSeek-R1 671B 版本的模型被称为“满血版”,这意味着它没有在参数规模上进行削减,仍然是完整的671B参数。但许多厂商和平台在宣传时,并未区分推理时的精度问题,而是将所有精度版本一概称为“满血版”,从而引发误导。

事实上,计算精度的不同,直接影响模型的推理效果,即使参数量相同,实际生成的文本质量和推理速度也会存在明显差异。
二、不同精度的实际影响
1、FP16(半精度推理)
计算精度:卓越
显存占用:极高(671B 参数约需 1.2T 显存)
推理速度:较慢
特点:
-
这是非常接近训练精度的版本,推理效果几乎与训练时一致。
-
由于占用显存极大,仅适用于A100 80G/H800等高端GPU,并且多卡推理才能支持完整加载。
2、INT8(量化推理)
计算精度:较高(但略有损失)
显存占用:降低约40%(671B 参数约需 740GB 显存)
推理速度:提高约30%-50%
特点:
1. 适用于显存受限的场景,如整机L20等。
2.对生成质量有一定影响,但总体较接近FP16,适合多数高性能推理需求。
3、INT4(极限量化推理)
计算精度:下降明显
显存占用:极低(671B 参数约需 380GB 显存)
推理速度:大幅提升(2-3倍)
特点:
1. 极端压缩模型,牺牲了一定的推理质量,以换取更快的速度和更低的显存需求。
2. 适用于算力极度受限的场景,如消费级GPU或边缘设备,但推理质量相比FP16/INT8有明显下降。
三、如何选择合适的版本
在选择DeepSeek 671B版本时,需要根据显存大小、计算需求、推理速度、生成质量等因素进行权衡:
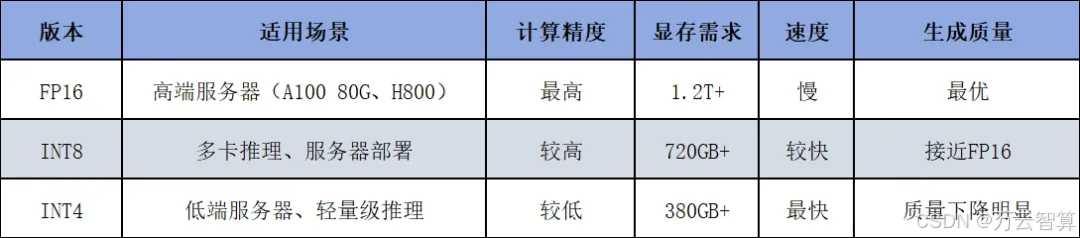
因此,如果你的目标是卓越质量的推理,FP16无疑是最优选择;如果你受限于显存,INT8是较好的折中方案;如果你需要优质的计算效率,INT4可以作为可选方案,但生成质量会受到一定影响。
不同版本的适用总结:
FP16
适用于追求卓越生成质量的场景,例如高级科研、企业级大模型推理,以及需要精确控制输出质量的应用。适用于拥有充足GPU资源(如A100 80G/H800集群)的用户。
INT8
适用于希望在保证较高质量的前提下降低显存占用和提升推理速度的场景,例如企业内部部署、云计算平台等。
INT4
适用于对生成质量要求不高,但需要优质算力优化的场景,例如边缘计算、轻量级应用、或消费级硬件上的部署。
四、结语
DeepSeek-R1 671B的“满血版”在不同精度下的推理效果差异巨大,因此在选择时需谨慎对比,不可盲目跟风。
如果追求卓越推理质量,FP16是最优解;如果希望在质量和效率之间取得平衡,INT8是合适的选择;而如果受限于算力资源,INT4可以作为折中方案。
理性选择适合自身业务需求的版本,才能真正发挥大模型的价值。
关于万云智算
万云智算是一家专注于算力资源管理和大模型应用开发的高科技企业,其覆盖教育、医疗、电商、科技、金融、政府公共服务等多种应用领域。顺应AI时代发展需求,万云智算以人工智能、大数据、云计算等前沿技术为引领,致力于为企业提供高效智能的解决方案。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)