【LLM训练框架】DeepSeek EPLB原理详解
MOE并行系列综述:💞目的:本系列是个人整理为了学习训练框架优化的,整理期间苛求每个知识点,平衡理解简易度与深入程度。🥰来源:材料主要源于进行的,每个知识点的修正和深入主要参考各平台大佬的文章,其中也可能含有少量的个人实验自证。🤭结语:如果有帮到你的地方,就和!!!!,后续继续完善和扩充👍(●’◡’●)
·

系列综述:
💞目的:本系列是个人整理为了学习训练框架优化的,整理期间苛求每个知识点,平衡理解简易度与深入程度。
🥰来源:材料主要源于【DeepSeek EPLB官方介绍】进行的,每个知识点的修正和深入主要参考各平台大佬的文章,其中也可能含有少量的个人实验自证。
🤭结语:如果有帮到你的地方,就点个赞和关注一下呗,谢谢🎈🎄🌷!!!
请先收藏!!!,后续继续完善和扩充👍(●’◡’●)
DeepSeek EPLB(Expert Parallel Load Balancing,专家并行负载均衡器)是DeepSeek公司为解决
混合专家(MoE)模型在分布式训练和推理中的负载不平衡问题而开发的优化策略。随着MoE模型规模的扩大,不同专家(Expert)的计算负载差异会导致GPU资源利用率低下,尤其在专家并行(Expert Parallelism)架构中,这种不均衡会加剧通信开销和资源浪费。EPLB作为DeepSeek开源技术的一部分,旨在提升计算效率并最大化系统性能
MOE并行
概述
- 背景
- 问题:传统大模型的参数规模不断增长,导致模型的训练和推理成本剧增。
- 解决方式:MOE通过
细粒度划分和稀疏激活机制在显著降低计算开销的同时保证了模型性能,从而支持万亿参数规模的扩展
- MOE具体原理链接地址
- MOE+数据并行
- 原理:在数据并行模式下包含MOE架构,门网络(gate)和专家网络都被复制地放置在各个运算单元上
- 问题:专家的数量受到单个计算单元的内存大小限制
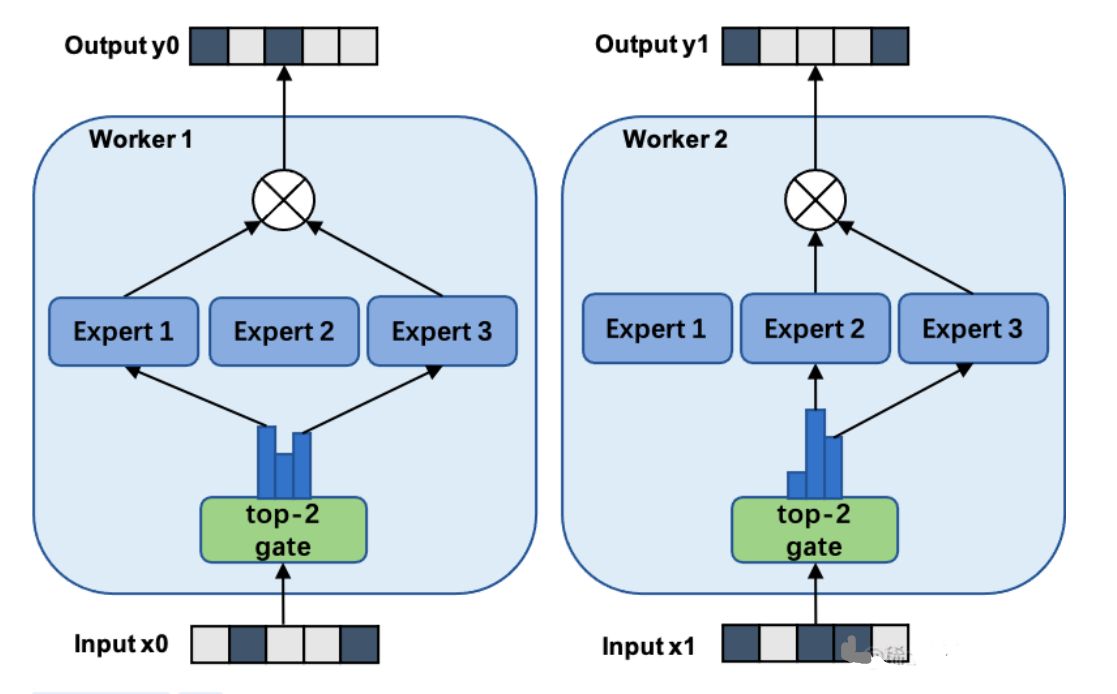
- MOE + 模型并行
- 原理:将同一个专家网络中专家放置到不同的计算单元上,从而实现更多的专家网络们同时被训练
- 问题:多设备间的专家并行训练会引入额外的通信开销
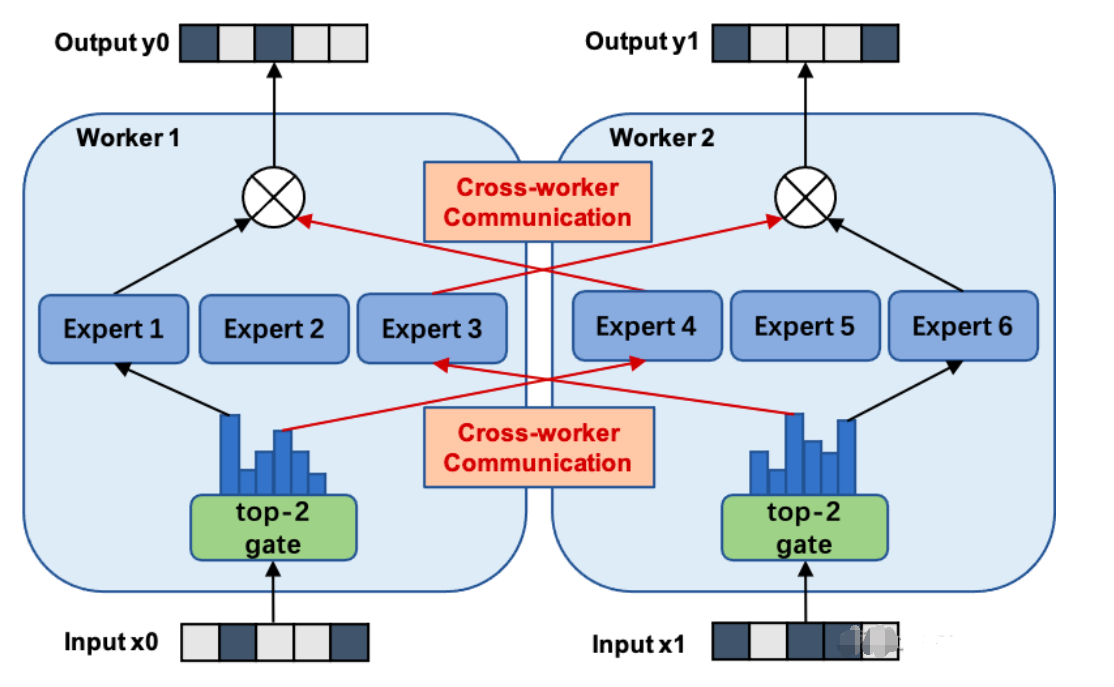
相关模型示例
- GShard
- 概述:GShard是由Google开发的一种分布式训练框架,首次将MoE思想引入Transformer架构,将编码器和解码器中每隔一个前馈网络(FFN)层替换为Top-2门控的MoE层
- 核心特点
- 稀疏激活:每个输入仅激活两个专家,第一个为权重最高的专家,第二个通过随机选择以平衡负载,从而使得模型参数可扩展至6000亿以上
- 专家容量平衡:路由到某专家的token数量超过最高可处理容量C时,超出的token会被标记为溢出,并通过残差连接直接传递到下一层或直接丢弃所有token
- 辅助损失:为了缓解“赢者通吃”问题,GShard设计了双重损失机制,通过主损失和辅助损失调节尽可能把token均分给各个专家
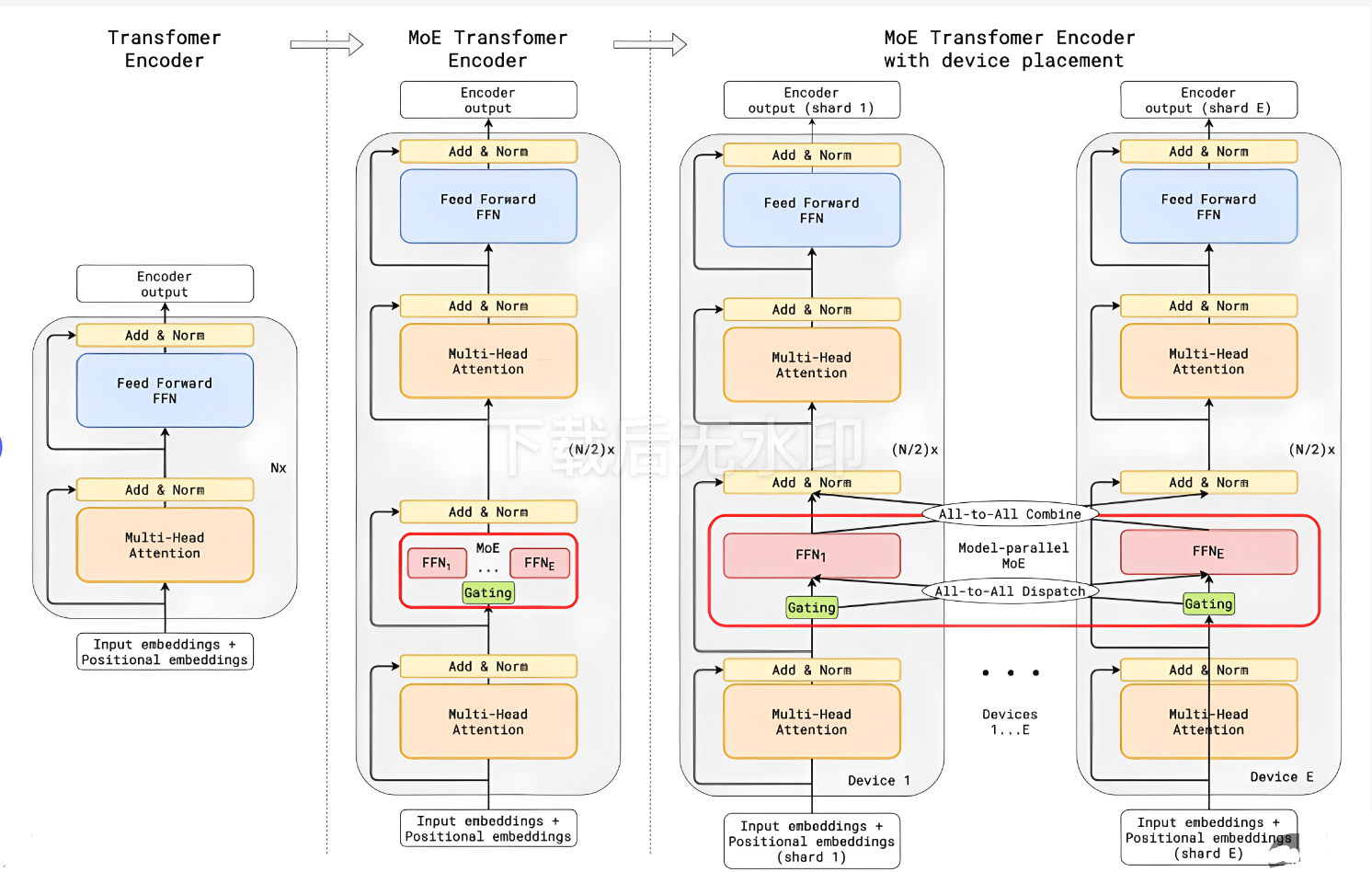
- Switch-Transformer
- 概述:Switch-Transformer是首个参数规模达万亿级别的模型,早期版本拥有1.6万亿参数(为GPT-3的9倍),通过稀疏激活技术有效利用硬件资源(如GPU/TPU),突破了传统全参模型的参数限制
- 核心特点
- 动态专家选择:每个输入仅激活一个最相关的Top-1专家(前馈神经网络子模块),降低通信和计算成本
- 负载均衡损失:引入损失项平衡专家使用频率,防止某些专家过载
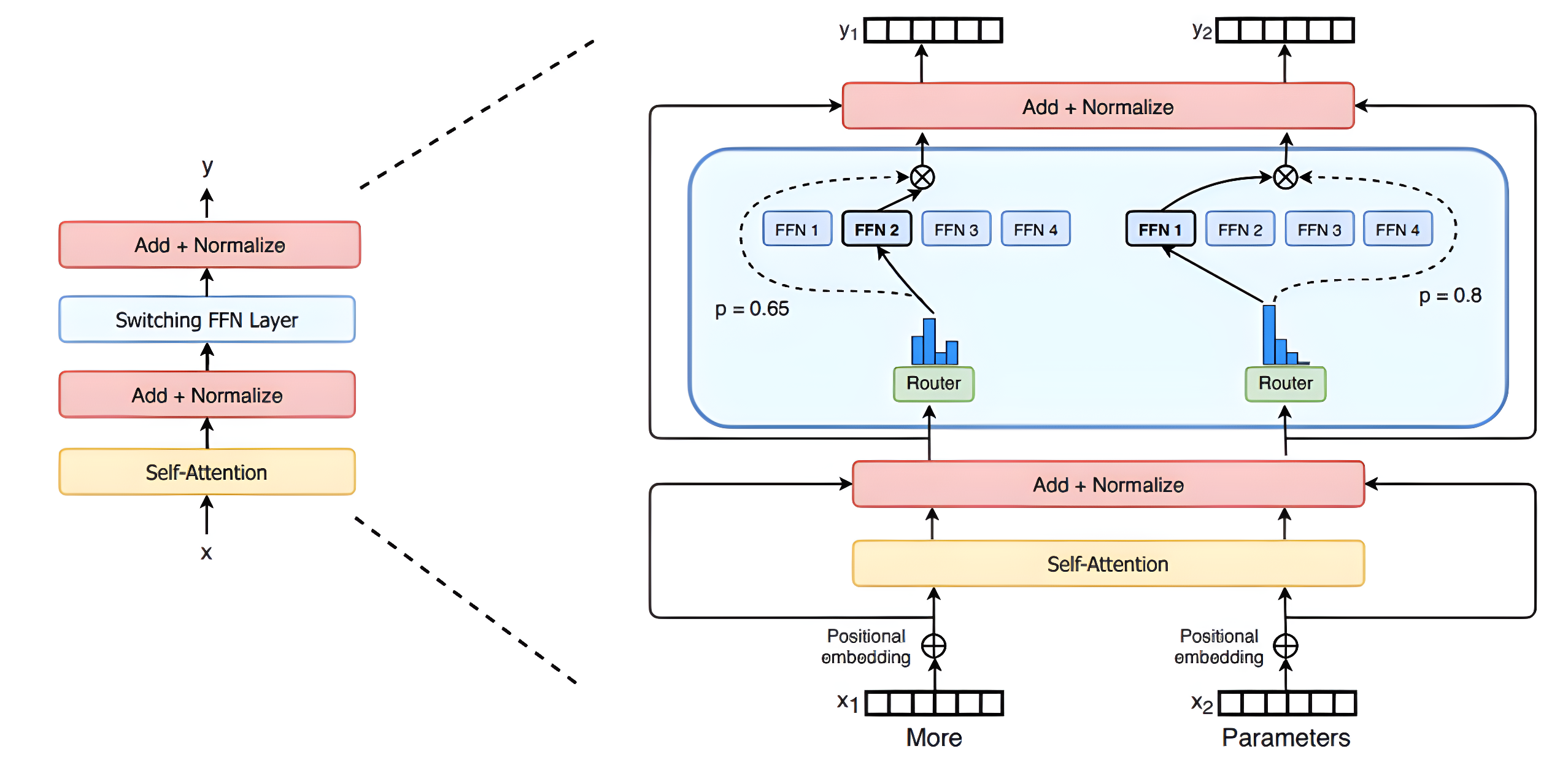
- GLaM
- 概述:谷歌于2021年提出的基于 混合专家架构(Mixture-of-Experts, MoE) 的稀疏激活语言模型,旨在通过动态选择子模型(专家)处理输入,实现高效扩展和低能耗。其最大版本拥有1.2万亿参数,是GPT-3的7倍,但训练能耗仅为GPT-3的1/3,推理计算需求减半
- 核心特点
- 稀疏激活:每层包含64个专家,每个输入token仅激活2个专家(占总参数的8%,约97B参数)
- 支持动态扩展:可通过增加专家数量或单个专家规模提升性能
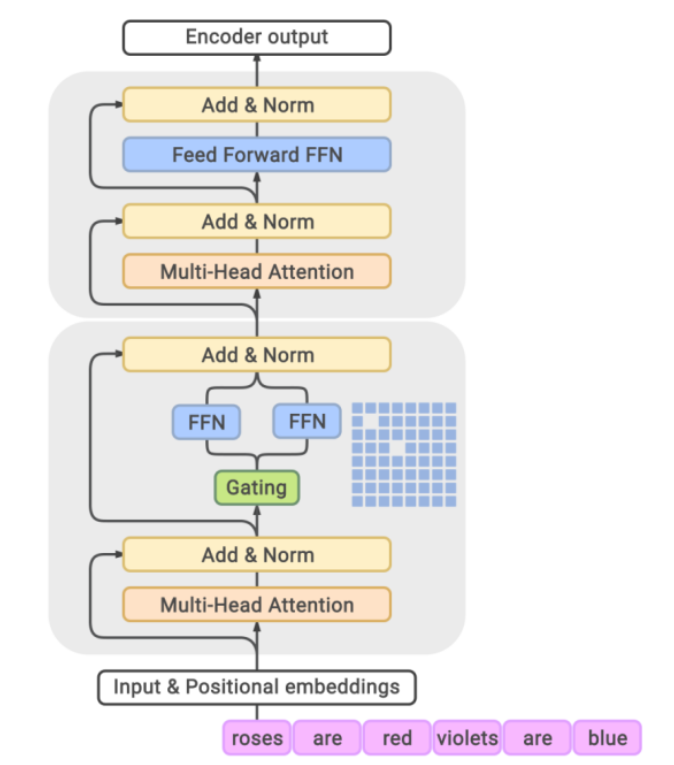
EBLP
概述
- 技术背景
- 问题:在混合专家模型(MoE)的分布式训练与推理中,不同专家因输入数据分布差异,可能面临部分GPU节点过载(计算资源耗尽)而其他节点闲置的负载不均衡问题,从而加剧跨节点通信开销,影响整体吞吐量和响应速度
- 解决方式:EPLB(Expert Parallel Load Balancer)通过动态调整专家间的计算负载分配,通过动态调度专家副本的负载分配,解决MoE模型在分布式训练和推理中的负载不平衡问题
- 基本原理
- 冗余专家策略:实时监控每个专家的计算负载,创建高负载专家副本,从而分散计算压力
- 通信优化:将关联性强的专家模块部署在同一计算节点,降低跨节点通信的数据量,从而减少网络带宽占用和延迟
- 无辅助损失的负载均衡:区别于传统方法需引入额外的负载均衡损失函数,EPLB通过可学习的偏置项(Bias Term),动态调整专家激活概率(降低高负载专家的激活权重,提升低负载专家的优先级),从而在不增加训练目标复杂性的情况下实现均衡
- 跨并行模式的协同优化:EPLB支持与数据并行(DP)、专家并行(EP)等多种并行策略协同工作,通过全局调度器协调不同并行模式下的资源分配,避免单一策略的局限性
- 系统架构
- 负载监控模块:实时采集各GPU节点的计算负载、显存占用及通信延迟等指标,为动态调度提供数据支持。
- 动态调度器:基于监控数据,采用贪心算法或强化学习策略生成负载迁移方案,从而将高负载节点的部分专家计算任务迁移至空闲节点,同时优化跨节点通信路径以减少延迟
- 缓存优化机制:通过KVCache硬盘缓存技术(命中率达56.3%),减少重复计算对负载均衡的干扰,进一步降低算力消耗
- 优点
- 资源利用率提升:在DeepSeek-V3的训练中,EPLB将GPU利用率提升超30%,减少因负载不均导致的节点空转现象
- 通信开销降低:通过优化专家任务的本地化计算,跨节点通信量减少约25%,尤其在高稀疏性MoE模型(如每层仅激活8/256个专家)中效果显著
源码
eplb.py
from typing import Tuple # 导入元组类型注解
import torch # 导入 PyTorch 库
def balanced_packing(weight: torch.Tensor, num_packs: int) -> Tuple[torch.Tensor, torch.Tensor]:
"""
采用贪心算法:将 n 个带权重的对象打包到 m 个包中,使得每个包恰好包含 n/m 个对象,并且所有包的权重尽可能平衡
参数:
- weight: 一个形状为 [X, n] 的 PyTorch 张量,代表每个物品的权重
- num_packs: 包的数量
返回:
pack_index: [X, n],每个物品所在的包的索引
rank_in_pack: [X, n],物品在包中的排名
"""
# 1.平均分组,从而实现包的权重平衡
num_layers, num_groups = weight.shape # 获取权重张量的层数和组数
assert num_groups % num_packs == 0 # 确保组数能被包数整除
groups_per_pack = num_groups // num_packs # 计算每个包中的组数
# 2. 特殊情况处理:如果每个包只有一个组,计算每个组的包索引和排名并返回,从而为后续的负载均衡提供信息
if groups_per_pack == 1:
# 生成每个组的包索引
pack_index = torch.arange(weight.size(-1), dtype=torch.int64, device=weight.device).expand(weight.shape)
rank_in_pack = torch.zeros_like(weight, dtype=torch.int64) # 生成每个组在包中的排名
return pack_index, rank_in_pack # 返回包索引和排名
# 3. 处理每个包含有多个分组的情况
indices = weight.float().sort(-1, descending=True).indices.cpu()# 对权重张量进行降序排序并获取索引,从而优先处理权重较大的组
pack_index = torch.full_like(weight, fill_value=-1, dtype=torch.int64, device='cpu')# 初始化包索引张量,初始值为-1表示未分配
rank_in_pack = torch.full_like(pack_index, fill_value=-1) # 初始化每个组在包中的排名张量,初始值为 -1
for i in range(num_layers): # 外层循环遍历每个包
pack_weights = [0] * num_packs # 初始化每个包的权重
pack_items = [0] * num_packs # 初始化每个包中的物品数量
for group in indices[i]: # 内层循环遍历当前层的每个组
# 核心:对于每个组,找到当前权重最小且物品数量未达到上限的包,将该组分配到这个包中。
pack = min((i for i in range(num_packs) if pack_items[i] < groups_per_pack),
key=pack_weights.__getitem__)
assert pack_items[pack] < groups_per_pack # 确保所选包中的物品数量未达到上限
pack_index[i, group] = pack # 记录当前组所在的包的索引
rank_in_pack[i, group] = pack_items[pack] # 记录当前组在包中的排名
pack_weights[pack] += weight[i, group] # 更新所选包的权重
pack_items[pack] += 1 # 更新所选包中的物品数量
return pack_index, rank_in_pack # 返回包索引和排名
def replicate_experts(weight: torch.Tensor, num_phy: int) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
创建冗余专家,具体是将 num_log 个逻辑专家复制为 num_phy 个物理专家副本,遍历冗余专家并将每个冗余专家映射到当前负载最大的逻辑专家
参数:
weight: [X, num_log] 形状的张量,代表每个逻辑专家的负载
num_phy: 复制后专家的总数
返回:
phy2log: [X, num_phy] 形状的张量,phy2log[i][j] 表示在第 i 个场景下,第 j 个物理专家对应的逻辑专家的 ID。
rank: [X, num_phy] 形状的张量,rank[i][j] 表示在第 i 个场景下,第 j 个物理专家是其对应逻辑专家的第几个副本
logcnt: [X, num_log] 形状的张量,logcnt[i][k] 表示在第 i 个场景下,第 k 个逻辑专家有多少个物理专家副本。
"""
# 1. 获取专家的相关信息
n, num_log = weight.shape # 获取权重张量的行数和逻辑专家数量
num_redundant = num_phy - num_log # 计算冗余专家的数量
assert num_redundant >= 0 # 确保冗余专家数量非负
device = weight.device # 获取权重张量所在的设备
# 2. 初始化映射和
phy2log = torch.arange(num_phy, dtype=torch.int64, device=device).repeat(n, 1) # 初始化物理专家到逻辑专家的映射
rank = torch.zeros(n, num_phy, dtype=torch.int64, device=device) # 表示每个物理专家在其对应的逻辑专家副本中的次序
logcnt = torch.ones(n, num_log, dtype=torch.int64, device=device) # 初始化每个逻辑专家的物理专家副本数量
arangen = torch.arange(n, dtype=torch.int64, device=device) # 生成一个从 0 到 n-1 的张量,n 代表组的数量
# 3. 复制逻辑专家为物理专家副本
for i in range(num_log, num_phy): # 遍历冗余专家(逻辑专家num_log到物理专家num_phy间为冗余的)
redundant_indices = (weight / logcnt).max(dim=-1).indices # 找到负载最大的逻辑专家的索引
phy2log[:, i] = redundant_indices # 将当前物理专家映射到负载最大的逻辑专家,更新 phy2log 张量
rank[:, i] = logcnt[arangen, redundant_indices] # 记录当前物理专家的副本排名,更新 rank 张量
logcnt[arangen, redundant_indices] += 1 # 更新负载最大的逻辑专家的副本数量,更新 logcnt 张量。
# 返回物理专家到逻辑专家的映射、副本排名和逻辑专家的副本数量
return phy2log, rank, logcnt
def rebalance_experts_hierarchical(weight: torch.Tensor, num_physical_experts: int,
num_groups: int, num_nodes: int, num_gpus: int):
"""
分层负载均衡策略,将逻辑专家复制为物理专家副本,并在节点和 GPU 层面进行负载均衡
参数:
weight: [num_moe_layers, num_logical_experts] 形状的张量,代表每个逻辑专家的负载
num_physical_experts: 复制后物理专家的总数
num_groups: 专家组的数量
num_nodes: 服务器节点的数量,节点内网络(如 NVLink)更快
num_gpus: GPU 的数量,必须是 num_nodes 的倍数
返回:
physical_to_logical_map: [num_moe_layers, num_physical_experts] 形状的张量,每个物理专家对应的逻辑专家的 ID
logical_to_physical_map: [num_moe_layers, num_logical_experts, X] 形状的张量,每个逻辑专家对应的物理专家的索引
logical_count: [num_moe_layers, num_logical_experts] 形状的张量,每个逻辑专家的物理专家副本数量
"""
# 1. 输入检查与初始化
num_layers, num_logical_experts = weight.shape # 获取权重张量的层数和逻辑专家数量
assert num_logical_experts % num_groups == 0 # 确保逻辑专家数量能被专家组数量整除
group_size = num_logical_experts // num_groups # 计算每个专家组中的专家数量
assert num_groups % num_nodes == 0 # 确保专家组数量能被节点数量整除
groups_per_node = num_groups // num_nodes # 计算每个节点中的专家组数量
assert num_gpus % num_nodes == 0 # 确保 GPU 数量能被节点数量整除
assert num_physical_experts % num_gpus == 0 # 确保物理专家数量能被 GPU 数量整除
phy_experts_per_gpu = num_physical_experts // num_gpus # 计算每个 GPU 上的物理专家数量
# 2. 定义逆排列计算辅助函数
def inverse(perm: torch.Tensor) -> torch.Tensor:
"""
计算排列的逆排列,接受一个排列张量 perm 作为输入,返回其逆排列
"""
inv = torch.empty_like(perm) # 初始化逆排列张量
# 计算逆排列
inv.scatter_(1, perm, torch.arange(perm.size(1), dtype=torch.int64, device=perm.device).expand(perm.shape))
return inv # 返回逆排列
# 3. 阶段的负载均衡
# 3.1 将专家组分配到节点上
tokens_per_group = weight.unflatten(-1, (num_groups, group_size)).sum(-1) # 计算每个专家组的总权重
group_pack_index, group_rank_in_pack = balanced_packing(tokens_per_group, num_nodes) # 使用 balanced_packing 函数将专家组分配到节点上
# 计算逻辑专家到中间逻辑专家的映射
log2mlog = (((group_pack_index * groups_per_node + group_rank_in_pack) * group_size).unsqueeze(-1) +
torch.arange(group_size, dtype=torch.int64, device=group_pack_index.device)).flatten(-2)
mlog2log = inverse(log2mlog) # 计算中间逻辑专家到逻辑专家的映射
# 3.2 在节点内创建冗余专家
tokens_per_mlog = weight.gather(-1, mlog2log).view(-1, num_logical_experts // num_nodes) # 计算每个中间逻辑专家的总权重
phy2mlog, phyrank, mlogcnt = replicate_experts(tokens_per_mlog, num_physical_experts // num_nodes) # 在节点内创建冗余专家
# 3.3 将物理专家分配到 GPU 上,借助中间物理专家这个中间层,能分阶段处理负载均衡问题
tokens_per_phy = (tokens_per_mlog / mlogcnt).gather(-1, phy2mlog) # 计算每个物理专家的总权重
pack_index, rank_in_pack = balanced_packing(tokens_per_phy, num_gpus // num_nodes) # 使用 balanced_packing 函数将物理专家分配到 GPU 上
phy2pphy = pack_index * phy_experts_per_gpu + rank_in_pack # 计算物理专家到中间物理专家的映射
pphy2phy = inverse(phy2pphy) # 计算中间物理专家到物理专家的映射
pphy2mlog = phy2mlog.gather(-1, pphy2phy) # 计算中间物理专家到中间逻辑专家的映射
pphy2mlog = (pphy2mlog.view(num_layers, num_nodes, -1) +
torch.arange(0, num_logical_experts, num_logical_experts // num_nodes).view(1, -1, 1)).flatten(-2)
pphy2log = mlog2log.gather(-1, pphy2mlog) # 计算物理专家到逻辑专家的映射
pphyrank = phyrank.gather(-1, pphy2phy).view(num_layers, -1) # 计算每个物理专家的副本排名
logcnt = mlogcnt.view(num_layers, -1).gather(-1, log2mlog) # 计算每个逻辑专家的副本数量
return pphy2log, pphyrank, logcnt # 返回物理专家到逻辑专家的映射、副本排名和逻辑专家的副本数量
def rebalance_experts(weight: torch.Tensor, num_replicas: int, num_groups: int,
num_nodes: int, num_gpus: int) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
专家并行负载均衡器的入口点。
参数:
weight: [layers, num_logical_experts],所有逻辑专家的负载统计信息
num_replicas: 物理专家的数量,必须是 `num_gpus` 的倍数
num_groups: 专家组的数量
num_nodes: 服务器节点的数量,节点内网络(例如,NVLink)更快
num_gpus: GPU 的数量,必须是 `num_nodes` 的倍数
返回:
physical_to_logical_map: [layers, num_replicas],每个副本对应的专家索引
logical_to_physical_map: [layers, num_logical_experts, X],每个专家对应的副本索引
expert_count: [layers, num_logical_experts],每个逻辑专家的物理副本数量
"""
# 1. 数据预处理
num_layers, num_logical_experts = weight.shape # 获取权重张量的层数和逻辑专家数量
weight = weight.float().cpu() # 将权重张量转换为 float 类型并移动到 CPU 上
# 2. 策略选择:如果专家组数量能被节点数量整除使用分层负载均衡,如果不能使用全局负载均衡
if num_groups % num_nodes == 0:
phy2log, phyrank, logcnt = rebalance_experts_hierarchical(weight, num_replicas,
num_groups, num_nodes, num_gpus)
else:
phy2log, phyrank, logcnt = replicate_experts(weight, num_replicas)
# 计算逻辑专家到物理专家的映射
maxlogcnt = logcnt.max().item() # 获取最大的逻辑专家副本数量
# 初始化逻辑专家到物理专家的映射
log2phy: torch.Tensor = torch.full((num_layers, num_logical_experts, maxlogcnt),
-1, dtype=torch.int64, device=logcnt.device)
# 计算逻辑专家到物理专家的映射
log2phy.view(num_layers, -1).scatter_(-1, phy2log * maxlogcnt + phyrank,
torch.arange(num_replicas, dtype=torch.int64, device=log2phy.device).expand(num_layers, -1))
# 返回物理专家到逻辑专家的映射、逻辑专家到物理专家的映射和逻辑专家的副本数量
return phy2log, log2phy, logcnt
# 定义模块的公共接口
__all__ = ['rebalance_experts']

参考博客
点击阅读全文

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0


 已为社区贡献2条内容
已为社区贡献2条内容






所有评论(0)