解锁大模型潜力:vLLM 集群部署 满血DeepSeek R1 671B大模型实战指南
导语: 大模型时代,如何高效部署和推理成为关键挑战。DeepSeek 是一个专注于中文理解和生成的大模型系列,涵盖了文本分类、情感分析、机器翻译、文本摘要等多个任务。其强大的语义理解和生成能力,为各种自然语言处理应用提供了有力支持。本文将带你深入探索 vLLM 集群部署 DeepSeek 大模型的实战技巧,解锁大模型应用的无限可能!近年来,大模型在自然语言处理、计算机视觉等领域取得了突破性进展,但
导语: 大模型时代,如何高效部署和推理成为关键挑战。DeepSeek 是一个专注于中文理解和生成的大模型系列,涵盖了文本分类、情感分析、机器翻译、文本摘要等多个任务。其强大的语义理解和生成能力,为各种自然语言处理应用提供了有力支持。 本文将带你深入探索 vLLM 集群部署 DeepSeek 大模型的实战技巧,解锁大模型应用的无限可能!
近年来,大模型在自然语言处理、计算机视觉等领域取得了突破性进展,但其庞大的参数量和计算需求也给部署和推理带来了巨大挑战。如何高效、稳定地运行大模型,成为开发者们关注的焦点。
vLLM:高效大模型推理引擎
vLLM 是一个基于 PagedAttention 的高效大模型推理引擎,专为处理超长序列和大规模模型而设计。它通过以下特性显著提升了大模型推理效率:
高效内存管理: 采用 PagedAttention 技术,将注意力机制的键值对存储在非连续内存中,有效减少内存碎片,提升内存利用率。
灵活部署: 支持单机多卡、多机多卡等多种部署方式,满足不同规模的应用需求。
易用性强: 提供简洁易用的 API,方便开发者快速集成到现有项目中。
部署架构图
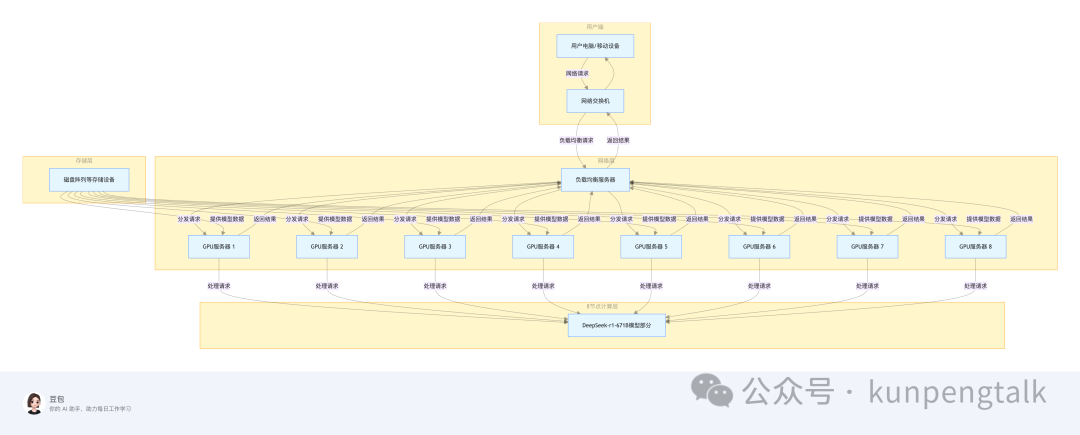
部署需求
-
集群节点:8 个节点
-
模型:DeepSeek r1 671B
-
网络:低延迟、高带宽网络,网络带宽 400G 以上(建议购买专业的网络设备)
-
GPU 资源:每个节点配置至少 8 张 A100 40GB GPU(或根据实际需求使用其他适合大模型的 GPU)
-
存储:SSD 存储,用于存放模型文件和缓存
集群架构
-
每个节点负责加载和运行模型的一部分,利用 模型并行性 和 数据并行性 以提高效率。
-
通信层:利用高速网络连接各个节点,确保模型和数据的同步。
- 组件
-
主节点:协调所有节点工作,负责接收请求、分发任务,并返回推理结果。
-
工作节点:负责模型的实际推理计算,每个工作节点可以负载多个 tensor parallel 或 pipeline parallel 切分的模型部分。
-
负载均衡器:确保请求均匀地分配到各个节点。
-
KV 缓存层:共享缓存存储,减少重复计算,提高响应速度。
-
监控系统:用于监控集群性能,可能包含 Prometheus 和 Grafana。
接下来,我们将一步步演示如何使用 vLLM 集群部署 DeepSeek 大模型,并进行推理。
1. 环境准备
-
安装 vLLM:
-
pip install vllm
2. 配置 vLLM 集群
-
编辑 vllm_config.yaml 文件,配置集群节点信息、模型路径、数据路径等参数。
-
启动 vLLM 集群:vllm start --config vllm_config.yaml
vllm_config.yaml 是用于配置 vLLM 引擎的 YAML 文件,它允许用户通过配置文件的方式灵活地设置 vLLM 的各项参数,从而优化大模型的推理性能和资源利用率。以下是对 vllm_config.yaml 中常见参数的详细介绍和解释:
vLLM 配置文件示例(vllm_config.yaml)
model: deepseek-r1-671b``tokenizer: deepseek-r1-671b``host: 0.0.0.0``port: 8000``api_keys: []`` ``# GPU 资源管理``gpu_memory_utilization: 0.85``max_num_seqs: 128``max_model_len: 4096``dtype: fp16``quantization: awq`` ``# 分布式设置``tensor_parallel_size: 8 # 在每个节点之间分配模型``worker_use_ray: true # 使用 Ray 进行分布式任务调度`` ``# 缓存设置``enable_chunked_prefill: true``block_size: 32`` ``# 日志和监控``log_level: INFO``enable_prometheus: true
- 模型加载相关参数
-
model: 指定要加载的 Hugging Face 模型名称或本地路径。例如,facebook/opt-125m 或 /path/to/local/model18。
-
tokenizer: 指定要使用的 Hugging Face tokenizer 名称或路径。如果未指定,默认使用与模型相同的 tokenizer18。
-
revision: 指定模型的版本(分支名称、标签名称或提交 ID)。默认使用最新版本18。
-
load_format: 指定模型权重的加载格式,支持 auto(默认)、pt(PyTorch)、safetensors 等18。
-
dtype: 设置模型权重和激活值的数据类型,支持 auto(默认)、float16、bfloat16 等18。
- 性能优化参数
-
tensor_parallel_size: 设置 Tensor 并行的 GPU 数量,用于多 GPU 分布式推理。例如,tensor_parallel_size: 4 表示使用 4 张 GPU24。
-
pipeline_parallel_size: 设置流水线并行的阶段数量,适用于多机多卡场景24。
-
gpu_memory_utilization: 设置 GPU 内存利用率,范围为 0 到 1。默认值为 0.9,表示使用 90% 的 GPU 内存24。
-
cpu_offload_gb: 将部分模型权重或中间结果卸载到 CPU 内存中,以扩展 GPU 内存。例如,cpu_offload_gb: 128 表示卸载 128GB 数据到 CPU24。
-
max_model_len: 设置模型的最大上下文长度(序列长度)。例如,max_model_len: 16384 表示支持最长 16K 的上下文24。
- 推理控制参数
-
max_num_batched_tokens: 每批次处理的最大 token 数量,用于优化吞吐量。例如,max_num_batched_tokens: 6000024。
-
max_num_seqs: 每次迭代的最大序列数量,用于控制并发请求数24。
-
enable_prefix_caching: 启用前缀缓存,减少重复计算,提升推理效率24。
-
quantization: 设置量化方法,减少内存占用。支持 bitsandbytes(8 位量化)和 fp8(FP8 量化)等24。
- 分布式与调度参数
-
distributed_executor_backend: 设置分布式推理的执行后端,支持 ray(默认)和 mp(多进程)24。
-
swap_space: 设置每个 GPU 的 CPU 换页空间(GiB),用于扩展 GPU 内存24。
-
scheduler_delay_factor: 设置调度器的延迟因子,用于优化请求调度8。
- 日志与调试参数
-
disable_log_stats: 禁用统计日志,减少性能开销24。
-
uvicorn_log_level: 设置 uvicorn Web 服务器的日志级别,支持 debug、info、warning 等24。
- 高级功能参数
-
enable_lora: 启用 LoRA(低秩适配器)功能,用于微调大模型24。
-
speculative_model: 设置推测解码的模型,用于加速推理8。
-
rope_scaling: 设置 RoPE 扩展参数,适用于长上下文模型(如 LLaMA)48。
由于官方是从huggingface去拉取大模型,由于墙的原因会安装失败,我们可以通过
https://hf-mirror.com/ 代理在下载模型
- 使用 Hugging Face 镜像下载 DeepSeek 模型权重:
#设置 Hugging Face 镜像
export HF_ENDPOINT=https://hf-mirror.com
#下载 DeepSeek 模型
vllm serve "deepseek-ai/DeepSeek-R1"
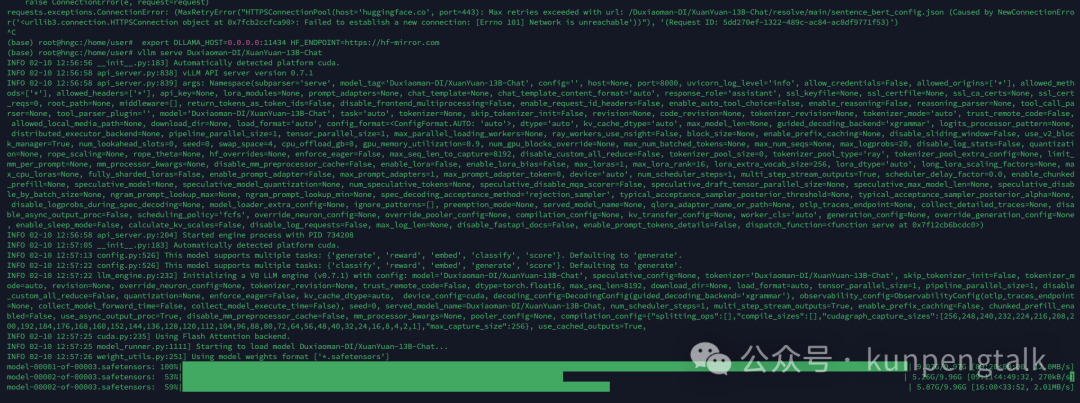
- 验证模型
# Call the server using curl:
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
] }'
3. 加载 DeepSeek 模型
from vllm import LLM
# 加载 DeepSeek 模型
llm = LLM(model="deepseek-model-path")
4. 进行推理
# 准备输入数据
input_text = "你好,世界!"
# 进行推理
output = llm.generate(input_text)
# 输出结果
print(output)
5.安装 OpenWebUI
如果你还没有安装 OpenWebUI,可以使用 Docker 方式部署:
docker run -d --name openwebui -p 3000:3000 -v openwebui-data:/app/data ghcr.io/open-webui/openwebui:main
或者使用本地安装方式:
git clone https://github.com/open-webui/open-webui.git
cd open-webuidocker compose up -d
-
配置 OpenWebUI 连接 vLLM
-
打开 OpenWebUI 界面(默认 http://localhost:3000)。
-
进入 Settings(设置) → LLM Providers。
-
添加新的 API 端点:
-
名称(Name): vLLM
-
API 地址(Base URL): http://127.0.0.1:8000/v1/
-
模型(Model): deepseek-r1-671b
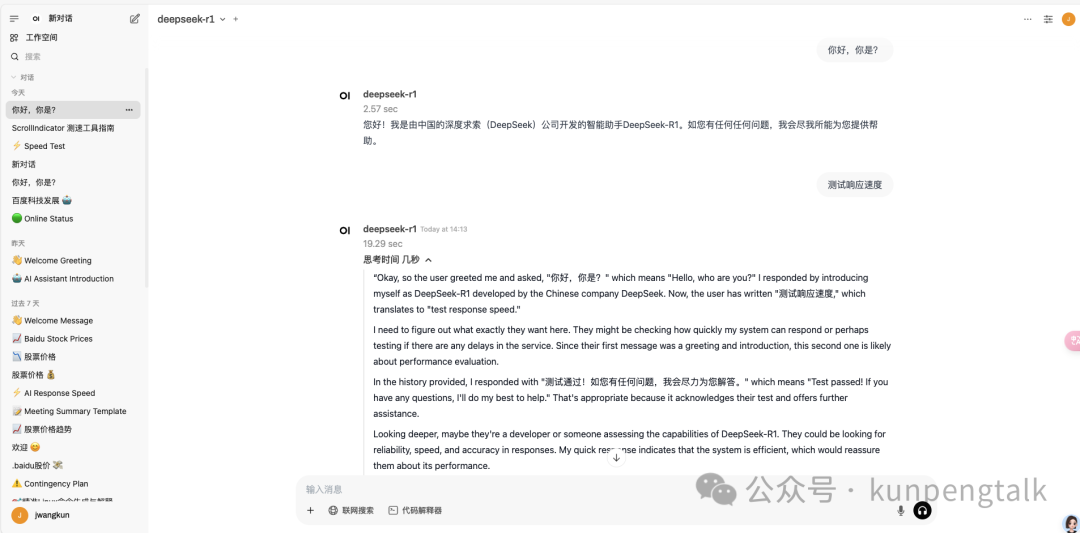
保存后,你就可以在 OpenWebUI 中使用 vLLM 作为推理后端了。
5. 性能优化
- 负载均衡:
- 根据模型请求的大小和复杂度,动态分配工作负载,避免某些节点超载。
- 内存与显存优化:
- 对 DeepSeek 671B 这样的超大模型,显存和内存是关键瓶颈。确保每个工作节点的显存足够容纳模型的某个子部分。
- 网络带宽:
- 在 8 节点的集群中,节点间通信非常频繁,因此需要高带宽低延迟的网络(如 InfiniBand)。
- 缓存层:
- 使用高效的缓存层来存储中间结果,减少重复计算。KV 缓存存储层可以是内存池或分布式缓存系统。
- 模型量化与优化:
- 对于 DeepSeek 671B 这类大模型,可以使用量化技术(如 AWQ)来减少显存占用,并通过 FP16 等精度优化提高推理速度。
总结
vLLM 集群部署 DeepSeek 大模型,为开发者提供了一种高效、稳定的大模型推理解决方案。通过本文的实战指南,相信你已经掌握了 vLLM 集群部署的基本流程和优化技巧。赶快行动起来,解锁大模型应用的无限可能吧!

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献278条内容
已为社区贡献278条内容

所有评论(0)